<div class="alert alert-warning"> <p><strong>O código fonte deste projecto pode ser obtido <a target="_blank" href="https://bitbucket.org/lfac/saraivas-fine-series">aqui</a>.</strong> </p> <p>Para utilizar a aplicaçăo basta instalar a <a target="_blank" href="http://www.playframework.org/">framework Play</a> (tem que ser uma versăo <strong>anterior ŕ 2.0</strong>, qualquer uma das versőes <strong>1.x.x</strong> serve sendo que a aplicaçăo foi desenvolvida na versăo <strong>1.2.4</strong>), ir ao directório da aplicaçăo e correr o comando <code>play run</code>. Se nada tiver sido alterado nos ficheiros de configuraçăo a aplicaçăo pode nesse momento ser acedida pelo endereço http://localhost:9000 .</p> </div>  # Objetivos do Projeto Os objetivos deste projeto podem-se separar em tręs categorias: navegaçăo, procura e recomendaçăo. Ao abordarmos cada um destes requisitos base foram criados requisitos mais específicos que correspondem a funcionalidades bem definidas. ## Navegaçăo 1.1 Dado um id válido de ator mostrar toda a informaçăo disponível sobre o mesmo numa página web dedicada. 1.2 Dado um id válido de criador mostrar toda a informaçăo disponível sobre o mesmo numa página web dedicada. 1.3 Dado um id válido de personagem mostrar toda a informaçăo disponível sobre a mesma numa página web dedicada. 1.4 Dado um id válido de série mostrar toda a informaçăo disponível sobre a mesma numa página web dedicada. 1.5 Fazer a listagem completa de séries, atores, criadores, anos, géneros e tags. 1.6 Permitir a navegaçăo via clique em referęncias a anos, géneros, tags, criadores, atores, séries e personagens. ## Procura 2.1 Pesquisa sintática baseada em número de ocorręncias das palavras na query. 2.2 Funcionalidade por defeito da pesquisa semântica: tentar fazer matching da query a um nome de uma instância de série, ator, personagem ou criador. 2.3 Estender 2.2 permitindo definir a classe que se pretende. 2.4 Estender 2.3 permitindo definir um filtro por predicado. 2.5 Estender 2.4 permitindo definir um filtro num intervalo (para os campos em que se aplique) 2.6 Estender 2.3 permitindo especificar uma outra classe (que terá de estar relacionada com a primeira). Os resultados da procura serăo todas as instâncias da segunda classe que se relacionem com as instâncias da primeira. Por exemplo todos os atores da série XYZ. 2.7 Tornar o matching de nomes de classes e predicados mais user-friendly năo considerando a capitalizaçăo e permitindo palavras semelhantes (por exemplo: series ser interpretado como TVSeries). 2.8 Permitir internacionalizaçăo com base em anotaçőes definidas na ontologia. ## Recomendaçăo 3.1 Fazer recomendaçőes com base no histórico de navegaçăo do utilizador. 3.2 Ter uma estratégia de fall-back para o caso de utilizadores sem histórico. 3.3 Permitir ver diretamente (sem abrir outra página) informaçăo relevante sobre as séries recomendadas (por exemplo: título e rating) 3.4 Ter uma vista dedicada que permita navegar visualmente todas as séries existentes na ontologia. 3.5 Estender 3.4 permitindo filtrar por ano e rating. # Abordagem e Arquitetura Nesta secçăo é descrita a abordagem seguida, o desenho das soluçőes, o design da arquitetura e săo explicadas as decisőes tomadas. ## Tecnologias  ## Ontologia A ontologia apresentada foi implementada de raiz uma vez que năo encontrámos nenhuma que considerássemos adequada para reutilizaçăo. Por exemplo, a Programmes Ontology (BBC, 2009) está relacionada com o nosso tema, mas aprofunda muitos conceitos sem interesse neste contexto como meio (canal de comunicaçăo) e acabaria por ser muito mais complexa que o necessário. O namespace escolhido para a ontologia foi: http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#. A ontologia foi criada no protégé versăo 4.1.0 e foi extraída no formato RDF/XML. 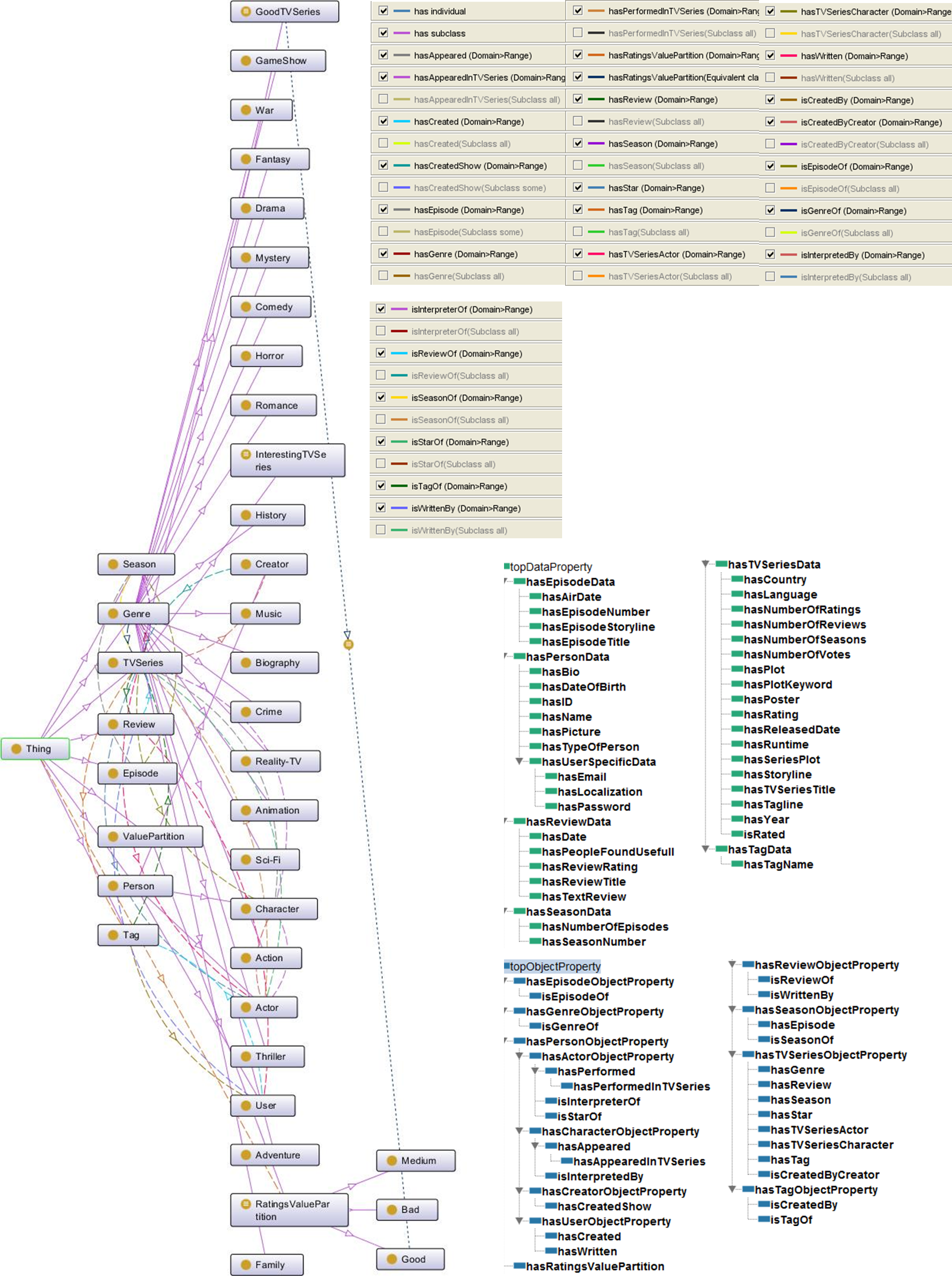 Esta ontologia tem como classe mais importante TVSeries que contém seasons que por sua vez contęm episodes. TVSeries pode ainda ter uma ou mais tags criadas por users, um ou mais géneros e uma ou mais reviews criadas também por users. Esta classe tem ainda criadores, atores e personagens representadas por atores. A classe Genre tem como subclasses todos os géneros que săo contemplados nas séries guardadas no nosso sistema. Já as instâncias de Tag tęm a propriedade hasTagName, que é uma data property com range string. A razăo desta distinçăo baseia-se na consideraçăo de que o número de géneros possíveis que faz sentido contemplar é finito (ao contrário do número de tags) e como tal parece-nos mais correto contemplá-los como classes na ontologia, uma vez que năo só fica explícito e automaticamente visível o que consideramos géneros, mas fica também controlado quando se acrescentam géneros. Por outro lado, podem existir várias tags escritas de várias formas diferentes que na realidade săo equivalentes (devido ŕ existęncia de sinónimos, diferentes perceçőes de questőes muito subjetivas e mesmo devido a erros ortográficos) o que causa uma fragmentaçăo de entidades que na realidade pertencem ao mesmo grupo lógico dentro do contexto. Este sistema de classificaçăo por tags é uma folksonomy e como tal tem as mesmas vantagens e desvantagens destes métodos colaborativos. O mesmo năo acontece com géneros que săo melhor controlados e săo finitos. Assim, há uma maior ponderaçăo no conjunto de géneros que o mantém controlado e finito. Isto é, evita-se que estes cresçam sem controlo e que sejam dados vários nomes diferentes a algo que seja o mesmo género, uma vez que este tem que existir na ontologia para ser atribuído. Uma Person pode ser User, Actor, Creator e Character. Consideramos que User é disjunta de todos. Especificamente é importante apontar que consideramos um User disjunta de Actor e Creator porque as entidades ator e criador săo mantidas pela aplicaçăo e năo pelas próprias pessoas. Contudo, um Creator pode ser também Actor logo estas classes năo săo disjuntas entre si. Adicionalmente, consideramos que Character pode ser interpretado por mais do que um Actor uma vez que tal é possível. Em alguns casos săo utilizadas anotaçőes na ontologia para esclarecer alguns detalhes. Săo usadas ainda anotaçőes com tag de língua (por exemplo “”@pt) para auxiliar a implementaçăo de pesquisas multilíngue utilizando as funcionalidades específicas do SPARQL para queries desta natureza. Utilizámos ainda o design pattern Value Partition para refinar a descriçăo da classe TVSeries. A nossa RatingsValuePartition restringe os possíveis valores de quăo boa é uma série em: Good, Medium ou Bad de acordo com a sua nota. Uma TVSeries vai ter um destes valores e, como já se deve ter tornado aparente, a escolha é mutuamente exclusiva. Dando uso a esta RatingsValuePartition criámos uma subclasse de TVSeries denominada de GoodTVSeries, que tem séries que tęm boa nota. Criámos ainda uma subclasse de TVSeries, InterestingTVSeries, que contém séries que satisfazem as condiçőes: + Ser subclasse de TVSeries. + Possuir mais de 30.000 avaliaçőes (nota atribuída por utilizadores). + Possuir mais de 100 revisőes. É importante notar, que apesar de termos as restriçőes definidas na ontologia criada no protégé, estas săo na realidade mantidas pela aplicaçăo aquando a populaçăo da ontologia. Refere-se ainda que seria possível obter esta mesma informaçăo por queries SPARQL, mas considerámos que assim ficaria mais explícito o que consideramos séries boas e séries interessantes e permitiu-nos experimentar algumas funcionalidades do protégé e ainda simplificar algumas queries SPARQL que sabíamos que pretendíamos utilizar bastante no futuro. O tutorial de ontologia de pizzas do protégé (Horridge, 2011) desaconselha, de forma geral, a especificaçăo de domains e ranges de propriedades, uma vez que estas condiçőes năo se comportam como restriçőes e podem causar resultados de classificaçăo “inesperados”. No entanto, a nossa ontologia năo é muito grande logo năo seria difícil descobrir efeitos secundários desta escolha e, desta forma, consideramos que compensa ter esta informaçăo valiosa para alguém que queira perceber a ontologia. Adicionalmente, o facto de estarmos a trabalhar numa área que está na vanguarda tecnológica leva-nos a considerar que é possível a evoluçăo e futura criaçăo de novas features que permitam tirar valor de escolhas que neste momento năo săo aproveitadas pelas ferramentas em uso. Adicionalmente, apesar de a ontologia ter sido exportada para RFD/XML, e por isso perder qualquer característica que năo seja fosse possível representar neste formato, decidimos definir características que só existem em OWL. Claro que algumas destas características podem cair em domínios extremamente complexos e até indecidíveis mas, mais uma vez, tęm valor para que o domínio de uso da ontologia esteja explícito, tanto para nós como para outros. De entre as características relevantes que definimos que acabam por mais tarde ser garantidas por nós destacam-se as características das propriedades dos objetos (como: functional, inverse functional, transitive, symmetric, etc.) que explicitámos exaustivamente quando considerámos adequado. Assim, a nossa ontologia apresenta várias relaçőes e características que facilitam a sua leitura e, ainda que muitas delas tenham que ser mantidas pela aplicaçăo, é útil tę-las explicitadas na ontologia. ## Arquitetura de Alto Nível A nossa soluçăo é constituída por 4 aplicaçőes: 1. WSTV Repository Builder – Constrói o repositório (neste caso um ficheiro) 2. WSTV Ontology Builder – Constrói a triple-store com a ontologia com base no ficheiro criado pelo Repository Builder. 3. WSTV Index Builder – Constrói o índice utilizado na pesquisa sintática. 4. WSTV Web – O portal web. Utiliza a triple-store e o índice. O WSTV Repository Builder constrói o repositório com base em duas fontes de dados: http://www.imdb.com/ (através de screen-scraping) e http://imdbapi.com/ (através de uma API em JSON). 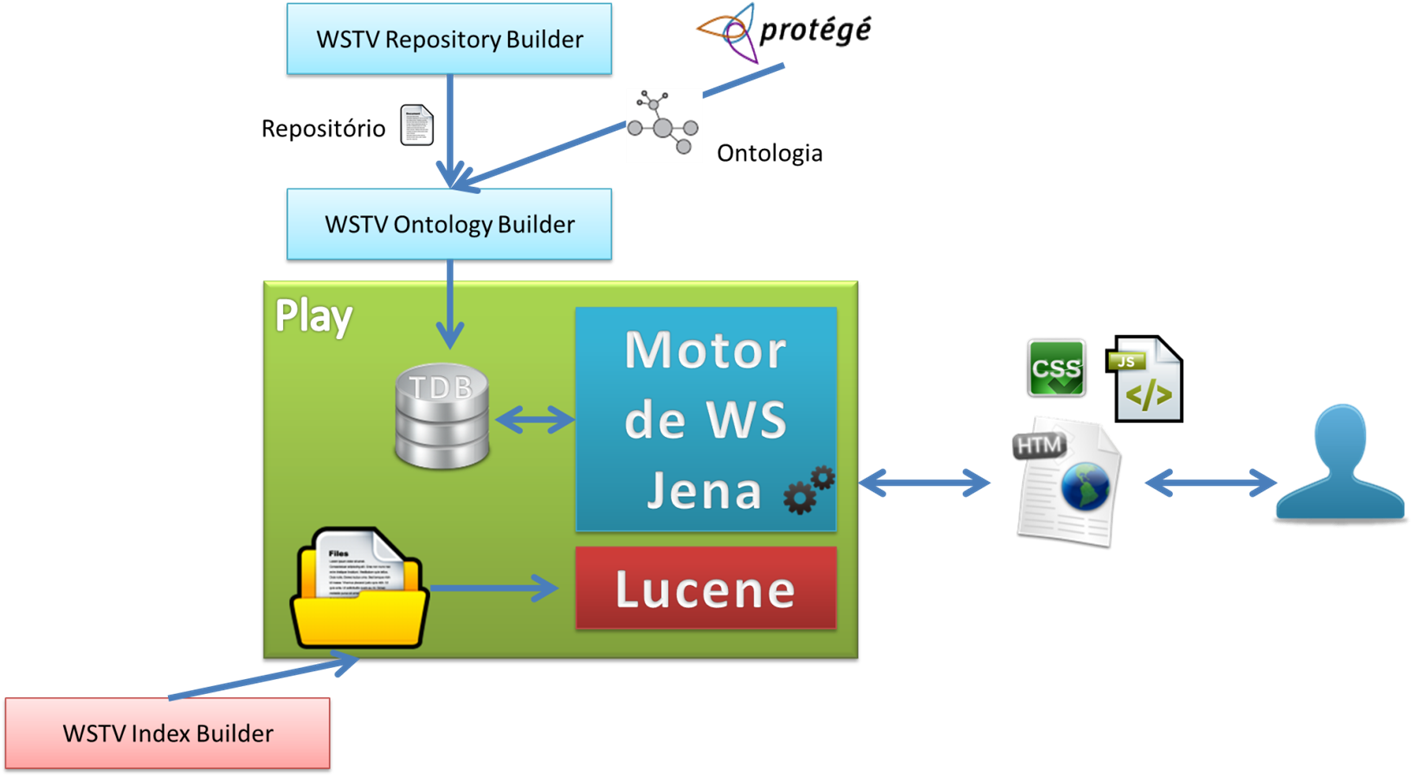 ## Componentes e Módulos da Aplicaçăo Web Dada a utilizaçăo da framework Play, ŕ partida a aplicaçăo web ficou estruturada segundo o modelo MVC: + Views – Templates baseados em HTML utilizados para mostrar a informaçăo que lhes é passada pelo Controller. + Controller – Neste caso só existe um Controller. Este é composto por várias açőes, sendo que cada uma corresponde a uma View com o mesmo nome. + Models – É aqui que está toda a lógica de Web Semântica: representaçőes em memória de séries, atores, personagens e criadores; queries SPARQL; acesso aos índices do Lucene; pós-processamento dos resultados das pesquisas; e algoritmo de recomendaçăo. ### Lista das Views/Controllers + *index* - Home-page. Contém a listagem completa de séries, atores, criadores, géneros, anos e tags bem como algumas recomendaçőes. + *name* - Apresenta todas as informaçőes disponíveis sobre um ator ou criador. + *title* - Apresenta todas as informaçőes disponíveis sobre uma série. + *char* - Apresenta todas as informaçőes disponíveis sobre um personagem. + *find* - Apresenta os resultados de uma pesquisa. + *visual* - Página do Visual Navigator. ### Classes que fazem parte dos Models + *JSONAssembler* - Traduz um objeto Java para uma String JSON. Utilizado para converter listas de séries. + *Pair* - Classe genérica que representa um Par. Muito útil para implementar rankings. + *Person* - Representa uma pessoa que neste caso pode ser um ator, criador ou personagem. + *Recomendations* - Implementa o algoritmo de recomendaçăo. + *SearchModel* - Classe base para as classes de procura. + *SearchResult* - Representa um resultado de uma pesquisa. + *SemanticSearch* - Implementa a pesquisa semântica. + *SemanticSearchUtils* - Implementa as funçőes que lidam diretamente com o motor SPARQL. + *Series* - Represente uma série de televisăo. + *SyntaticSearch* - Implementa a pesquisa sintática. + *TripleStoreManager* - Gere a ligaçăo ŕ triple-store. + *TSModel* - Classe base para Models baseados em dados na triple-store. Classe măe de Person e Series. + *Utils* - Contém funçőes utilitárias. ### Pesquisa Sintática A pesquisa sintática utiliza um índice construído pela ferramenta Lucene. O processo de construçăo é executado na aplicaçăo WSTV Index Builder e é constituído pelas seguintes fases: 1. A página inicial (index) é adicionada ŕ fila de páginas para analisar. 2. Se a fila estiver vazia termina. Se năo passa a 3. 3. É tirada uma página da fila e é verificado se o seu url já foi analisado. Se năo, passa a 4 se sim volta a 2. 4. Caso năo tenha sido processada, a página é analisada tanto a nível de ocorręncias de palavras como a nível de links existentes. Todos os urls dos links săo adicionados ŕ fila. Volta a 2. Há que notar que os links para pesquisas năo săo considerados e que links diferentes que apontem para o mesmo recurso săo filtrados. Quando o utilizador insere uma query e escolhe o modo de pesquisa “Statistic” na aplicaçăo web, a query é passada ao Lucene que devolve um conjunto de resultados ordenado pelo número de hits das keywords inseridas. Por uma questăo de simplicidade apenas săo exibidos no máximo 20 resultados. ### Pesquisa Semântica Nesta subsecçăo é descrita a implementaçăo da procura semântica. #### i. Parsing de Queries Dado que năo era objetivo deste trabalho utilizar técnicas elaboradas de Natural Language Processing (NLP) foram feitas algumas simplificaçőes a nível do parsing de queries de procura semântica, nomeadamente: + As queries tęm de seguir uma estrutura pré-definida (ver tabela). É de notar que existe um mecanismo de reserva caso a query năo siga a estrutura. Nesse caso é assumida a estrutura #1, apresentada na tabela, que se baseia em assumir que todas as keywords da pesquisa săo uma instância a pesquisar de uma qualquer classe. + Classes, predicados e separadores tęm de ser obrigatoriamente representados por palavras singulares, isto é, uma classe năo pode ser representada por “Series de TV”. Esta restriçăo de nomenclatura só se aplica ŕs palavras utilizadas nas queries e năo ŕs outras componentes do projeto. ##### Estrutura válida das queries. Estar dentro de [] significa que podem ser colocadas várias instâncias separadas por "and". <table class="table"> <thead> <tr> <th>#</th> <th>Estrutura</th> <th>Objectivo</th> </tr> </thead> <tbody> <tr> <td>1</td> <td>«valor»</td> <td>2.2</td> </tr> <tr> <td>2</td> <td>«classe» «valor»</td> <td>2.3</td> </tr> <tr> <td>3</td> <td>«classe» [«predicado» «valor»]</td> <td>2.4</td> </tr> <td>4</td> <td>«classe» [«predicado» from «valor» to «valor»]</td> <td>2.5</td> </tr> <td>5</td> <td>«classe» «valor» «classe 2»</td> <td>2.6</td> </tr> </tbody> </table> A nossa soluçăo, apesar de restritiva, permite bastante flexibilidade. Destacam-se algumas características, por exemplo: + As procuras săo case-insensitive. + Săo permitidos sinónimos (por exemplo TVSeries ? Series). + Permite escolher entre pesquisa em Inglęs e Portuguęs. Esta funcionalidade só está parcialmente implementada já que era apenas uma prova de conceito. As propriedades que podem ser utilizadas em Portuguęs săo título, da classe Series, e ano da mesma classe. A cada uma das estruturas na tabela corresponde uma funçăo a que chamamos de primitiva. Cada uma destas funçőes recebe como parâmetros os campos referidos na tabela, com a ressalva de que quando existem intersecçőes estas săo tratadas separadamente, ou seja, é feita uma chamada ŕ primitiva por cada condiçăo. Tal decisăo foi tomada para simplificar a implementaçăo e teste das primitivas e aumentar a modularidade e potencial de reutilizaçăo do código. A deteçăo da estrutura é feita com base em funçőes que, conforme a língua escolhida pelo utilizador, tentam encontrar correspondęncias entre as palavras na query e a forma correta (igual ŕ que está na ontologia). Caso năo exista nenhuma correspondęncia é devolvido null. Existem funçőes para traduzir classes, predicados e predicados numéricos (aos quais é possível aplicar um intervalo). Por outras palavras, para descobrir a estrutura das keywords usadas na pesquisa săo utilizadas as funçőes para determinar se determinada keyword é classe ou propriedade, por exemplo. A funçăo try2Resolve2Class(String w) tem o nome das classes e os sinónimos e tenta fazer a correspondęncia devolvendo o nome exato da classe (como apresentado na ontologia) ou null se năo for feita correspondęncia. Por exemplo podemos chamar *try2Resolve2Class*(“Series”) e obtemos como return “TVSeries”. A funçăo *try2Resolve2Prop*(String classWord, String propWord, String language) é um pouco mais elaborada (uma vez que existe um grande número de propriedades na ontologia, o que tornou necessário automatizar a tarefa de as percorrer). Com este objetivo é utilizada uma query para encontrar todas as subclasses da classWord que tenham determinada propriedade. Logo que seja encontrada uma um caso que satisfaça a condiçăo é devolvida a propriedade (uma vez que na ontologia năo existem duas propriedades diferentes com nomes iguais). Năo foi implementado registo de utilizadores, login e recomendaçőes semânticas baseadas em histórico guardado por utilizador (foi sim implementada recomendaçăo semântica baseada em histórico guardado na sessăo do browser), uma vez que tal năo ia contribuir para a complexidade ou interesse da vertente semântica da nossa aplicaçăo. A gestăo de utilizadores neste contexto năo está relacionada com web semântica e sugestőes por histórico de conta seriam uma simples extensăo de sugestőes baseadas no histórico da sessăo. #### ii. Primitivas Na estrutura #1 é assumido que as palavras de procura săo um valor que pode corresponder ŕ instância de qualquer classe cujos elementos tenham as suas próprias páginas, como tal realiza-se a procura comparando com todas as instâncias das classes Actor, Creator, Character e TVSeries, unindo-se todos os resultados de procura num conjunto. Por outras palavas, é chamada quatro vezes a funçăo *find*(String className, String instance), sendo que className vai assumir os valores “Actor”, “TVSeries”, “Character” e “Creator” e instance vai ter as keywords usadas na pesquisa. Como exemplo se procurarmos a atriz Emma Bell, as queries SPARQL utilizadas seriam semelhantes ŕ seguinte: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> PREFIX foaf2: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT ?s WHERE { ?s foaf2:type foaf:Actor . ?s foaf:hasName ?instanceName . FILTER regex(?instanceName, "Emma Bell", "i" ) } ``` A flag “i” torna as correspondęncias ŕs expressőes regulares case-insensitive. Para a estrutura #2 é novamente utilizada a funçăo *find*(String className, String instance) e quando o className corresponde a Actor, Creator, Character ou TVSeries a query SPARQL utilizada é semelhante ŕ anterior. Contudo, existem ainda casos especiais como para as classes Tag ou Genre. Para Genre por exemplo a query seria a seguinte: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> SELECT ?s WHERE { ?s foaf:hasGenre foaf:"+instance+"} ``` Na estrutura #3 é utilizada a funçăo *findByProp*(String className, String propName, String propValue, String language). Nesta funçăo mapeiam-se os parâmetros para className, que tem propriedade propName com o valor propValue. A query SPARQL utilizada é a seguinte: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> PREFIX foaf2: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf3: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?s WHERE { { {?s foaf2:type foaf:"+className+"} UNION {?s foaf3:subClassOf foaf:"+className+"} } . ?s foaf:"+propName+" ?o . FILTER regex(?o, \""+propValue+"\", \"i\" )} ``` Se o parâmetro language fosse Portuguęs, o mapeamento com propName seria usado em relaçăo ŕ anotaçăo em Portuguęs da propriedade. A query para este caso seria: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> PREFIX foaf2: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf3: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?s WHERE { { {?s foaf2:type foaf:"+className+"} UNION {?s foaf3:subClassOf foaf:"+className+"} } . ?propo foaf3:comment \""+propName+"\"@pt . ?s ?propo ?o . FILTER regex(?o, \""+propValue+"\", \"i\" )} ``` Note-se que por defeito a aplicaçăo lida com as queries em Inglęs. Na estrutura #4 é utilizada a funçăo *findByRange*(String className, String proposition, double start, double end). Por exemplo, se estivermos a fazer uma range query de séries entre dois anos, a query é a seguinte: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> PREFIX foaf2: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf3: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?s WHERE { { {?s foaf2:type foaf:"+className+"} UNION {?s foaf3:subClassOf foaf:"+className+"} } . ?s foaf:"+proposition+" ?year . FILTER (?year > "+start+") . FILTER (?year < "+end+")} ``` Como se pode observar é possível utilizar os filtros do SPARQL diretamente (de forma semelhante ao SQL) para restringir valores numéricos. Na estrutura #5 vai-se encontrar a instância (ou instâncias) da primeira classe e de seguida devolver as instâncias da segunda classe relacionadas com a primeira instância. Exemplos de procura seriam: + “Series south Actor” que irá encontrar instâncias “south” da classe TVSeries e de seguida devolver instâncias de Actor relacionadas com essa instância. Por outras palavras, os resultados seriam links para as páginas dos atores da série south park. + “Actor Summer Glau Series” vai encontrar todas as séries em que a atriz Summer Glau tenha participado. A funçăo utilizada é *find*(String className, String instance, String assocClassName). Esta funçăo começa por chamar a funçăo *find*(String className, String instance) com os dois primeiros parâmetros (className e instance). Um exemplo desta query para o segundo caso seria: ``` <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> PREFIX foaf2: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT ?s WHERE { ?s foaf2:type foaf:Actor . ?s foaf:hasName ?instanceName . FILTER regex(?instanceName, "Summer Glau", "i" ) } ``` De seguida văo-se buscar todas as propriedades possíveis para unir a instância ŕ segunda classe. Tomando novamente como exemplo a segunda pesquisa semântica as propriedades possíveis entre a instância “Summer Glau” da classe Actor e TVSeries săo as Object Properties *hasPerformedInTVSeries* e *isStartOf*. Tendo esta informaçăo văo-se buscar as instâncias que estăo relacionadas com a Actor Summer Glau (com identificador único nm1132359) através destas propriedades. Um exemplo desta query é apresentado de seguida: ``` PREFIX foaf: <http://www.semanticweb.org/ontologies/2011/9/WSTV.owl#> SELECT ?o WHERE { { foaf:nm1132359 foaf:hasPerformedInTVSeries ?o } UNION { foaf:nm1132359 foaf:isStarOf ?o } } ``` ### Algoritmo de Recomendaçőes As recomendaçőes feitas ao utilizador tęm como base o seu histórico de visualizaçăo de páginas de séries durante a sessăo. A visualizaçăo de atores, criadores e personagens năo tem qualquer influęncia na recomendaçăo. Uma das razőes desta decisăo é que essa informaçăo já pode ser consultada na secçăo de filmografia, ao aceder ŕ página da pessoa. Contudo, a razăo principal para năo fazermos sugestőes com base em eixos, como por exemplo ator, é que temos uma base de dados de séries relativamente pequena na qual é raro um ator ter participado em mais do que uma série. Quando o utilizador năo tem histórico săo recomendadas séries que fazem parte de um conjunto de séries de alta qualidade e/ou interessantes definido na ontologia. O propósito é que é preferível recomendar séries de qualidade do que năo recomendar nenhuma ou usar um critério aleatório. Além disso, de todas as N séries neste conjunto só săo recomendadas no máximo 4, escolhidas aleatoriamente e năo ordenadas (para evitar que se sugiram sempre as mesmas). Com base no histórico do utilizador săo construídos dois histogramas, um de géneros e outro de criadores. Estes histogramas văo contar todas as ocorręncias de um determinado género ou criador. É de notar que năo foram descartadas séries que aparecem no histórico mais que uma vez – se essas séries foram mais visitadas os seus atributos devem ter mais relevância. Com base nos dois histogramas é calculada a pontuaçăo de todas as séries no dataset. Esta pontuaçăo (ou P) é calculada da seguinte forma: 1. Inicia P a 1. 2. Para todos os géneros, adiciona a P o valor desse género no histograma. 3. Para todos os criadores, adiciona a P o valor desse criador no histograma. 4. Multiplica P pelo rating da série dividido por 10. O objetivo do passo 4 é, sobretudo, evitar que séries de muito baixa qualidade sejam recomendadas. P é iniciado a 1 para que, caso existam poucas correspondęncias com géneros ou criadores, as restantes séries sejam ordenadas pelo seu rating. Por fim, as séries săo ordenadas por P e săo recomendadas as 5 melhor classificadas de acordo com este sistema. De notar que séries no histórico năo săo recomendadas (porque o utilizador já as viu), nem a série que o utilizador possa estar a ver no momento. ### Visual Navigator O Visual Navigator é um hibrido entre navegaçăo e recomendaçăo. A ideia base é ver, num plano 2D, o quăo próximo estăo todas as séries no dataset de uma série alvo. Quanto maior essa proximidade menos distantes do centro aparecerăo as séries. Para tornar a visualizaçăo mais interessante cada série é representada pela sua imagem sendo que o tamanho desta também reflete (de forma equivalente ŕ distância ao centro) a afinidade com a série alvo (maior - mais próxima). A proximidade é baseada numa pontuaçăo – a mesma utilizada para as recomendaçőes. O algoritmo e o código săo os mesmos, a única diferença é que neste caso a única série no “histórico” é a série alvo (de notar que a utilizaçăo desta feature năo altera de forma nenhuma a funcionalidade de recomendaçăo). Também é possível filtrar as séries visíveis por ano e rating. Esta funcionalidade é exemplo das vantagens da modularidade da aplicaçăo web. Em termos de back-end, implementar esta feature limitou-se ŕ utilizaçăo da componente de pesquisa semântica por intervalo. Além das referidas existe ainda mais uma série de funcionalidades para enriquecer a experięncia do utilizador: + On mouse over mostra uma tooltip com o título, ano, rating e géneros da série. Também faz zoom ŕ imagem e coloca-a ŕ frente de outras que eventualmente se estiverem a sobrepor. + Ao clicar na série alvo é aberta a sua página num novo separador. + Clicar numa série que năo a alvo faz com que essa se torne o alvo. 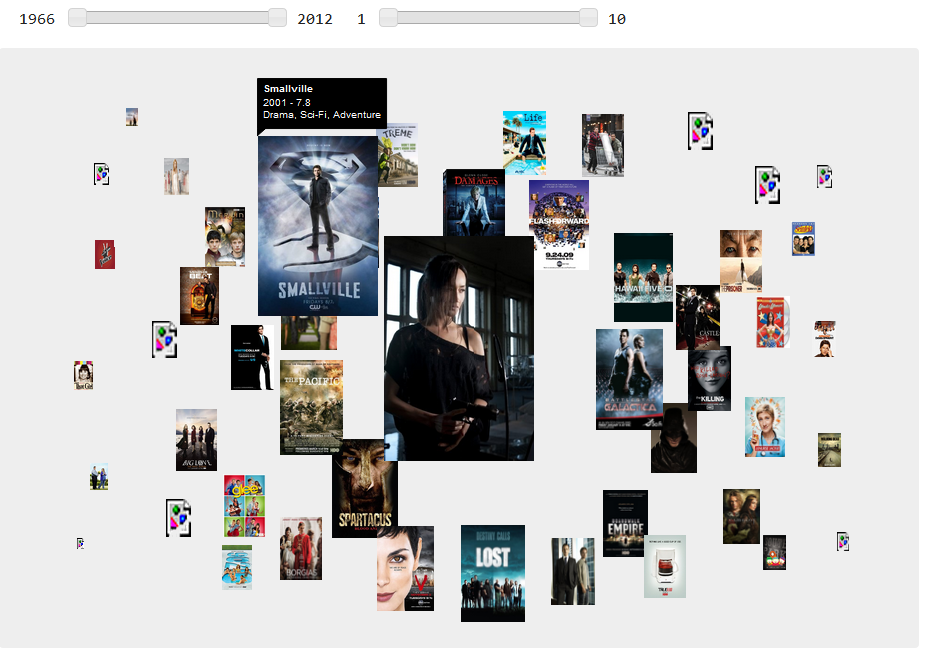 <hr/> <div class="alert alert-warning"> <a target="_blank" href="http://student.dei.uc.pt/~catre/" >Pedro Gil Catré</a> & <a target="_blank" href="http://student.dei.uc.pt/~lfac/">Luís Filipe Cardoso</a>. Web site criado com http://strapdownjs.com/ <p>Copyright © 2012</p> </div>